JSON Importer
ArcadeDB is able to import data from JSON format. Thanks to the flexible mapping, it’s possible to define the rules of conversion between the input json file and the graph.
Let’s start from this simple JSON file to import as an example. The file contains a flat structure of records with a relationship of employee and manager:
{
"Users":[
{
"EmployeeID":"1234",
"ManagerID":"1230",
"Name":"Marcus"
},
{
"EmployeeID":"1230",
"ManagerID":"1231",
"Name":"Win"
}
]
}First, create a new database "employees" by using the console:
> CREATE DATABASE employeesThen execute the following command (assuming the file above is saved in the local directory as employees.json:
{employees}> IMPORT DATABASE employees.json WITH mapping = {
"Users": [{
"@cat": "v",
"@type": "User",
"@id": "id",
"@idType": "string",
"@strategy": "merge",
"EmployeeID": "@ignore",
"ManagerID": {
"@cat": "e",
"@type": "HAS_MANAGER",
"@cardinality": "no-duplicates",
"@in": {
"@cat": "v",
"@type": "User",
"@id": "id",
"@idType": "string",
"@strategy": "merge",
"EmployeeID": "@ignore",
"id": "<../ManagerID>"
}
}
}]
}The mapping file is a JSON snippet with directives about what to import, what to ignore and how to map edges with JSON objects. Below all the supported tags:
-
@cat: is the category of record to use between "v" for vertex, "e" for edge and "d" for document -
@type: is the type name to use on record creation. If the type doesn’t exist, it’s implicitly created during the import -
@id: is the property that works as primary key. if not already defined, a unique index is created on the configured@idproperty -
@idType: is the type of the primary key in the@idproperty. If not defined, the type is taken from the first value found. In case of numbers, the JSON parser always uses DOUBLE as a type. You can, for example, use LONG to force using LONG instead of DOUBLE -
@cardinality: if "no-duplicates", the edges are not created if there is an edge of the same type between the two vertices -
@strategy: represents the strategy to use when the record with the configured@idalready exists By default the existent record is used, but the "merge" strategy allows to merge the current record with the existent one. The current properties will overwrite the existent ones -
@in: used for edges and represents the destination vertex for the edge -
@ignore: ignore the property, do not import into the database
Note the "id" property in the manager is taken by using "<../ManagerID>" that means get the property "ManagerID" from the parent (../).
How to import a JSON file with a hierarchical structure? Let’s look at the second example coming from the JSON export of food and nutrients from the U.S. DEPARTMENT OF AGRICULTURE website (USDA). USDA provides updated files to download in both CSV and JSON format.
First, create a new database "food" by using the console:
> CREATE DATABASE foodThen execute the following command:
{food}> IMPORT DATABASE https://fdc.nal.usda.gov/fdc-datasets/FoodData_Central_foundation_food_json_2022-10-28.zip WITH mapping = {
"FoundationFoods": [{
"@cat": "v",
"@type": "<foodClass>",
"foodNutrients": [{
"@cat": "e",
"@type": "HAS_NUTRIENT",
"@in": "nutrient",
"@cardinality": "no-duplicates",
"nutrient": {
"@cat": "v",
"@type": "Nutrient",
"@id": "id",
"@idType": "long",
"@strategy": "merge"
},
"foodNutrientDerivation": "@ignore"
}],
"inputFoods": [{
"@cat": "e",
"@type": "INPUT",
"@in": "inputFood",
"@cardinality": "no-duplicates",
"inputFood": {
"@cat": "v",
"@type": "<foodClass>",
"@id": "fdcId",
"@idType": "long",
"@strategy": "merge",
"foodCategory": {
"@cat": "e",
"@type": "HAS_CATEGORY",
"@cardinality": "no-duplicates",
"@in": {
"@cat": "v",
"@type": "FoodCategory",
"@id": "id",
"@idType": "long",
"@strategy": "merge"
}
}
}
}]
}]
}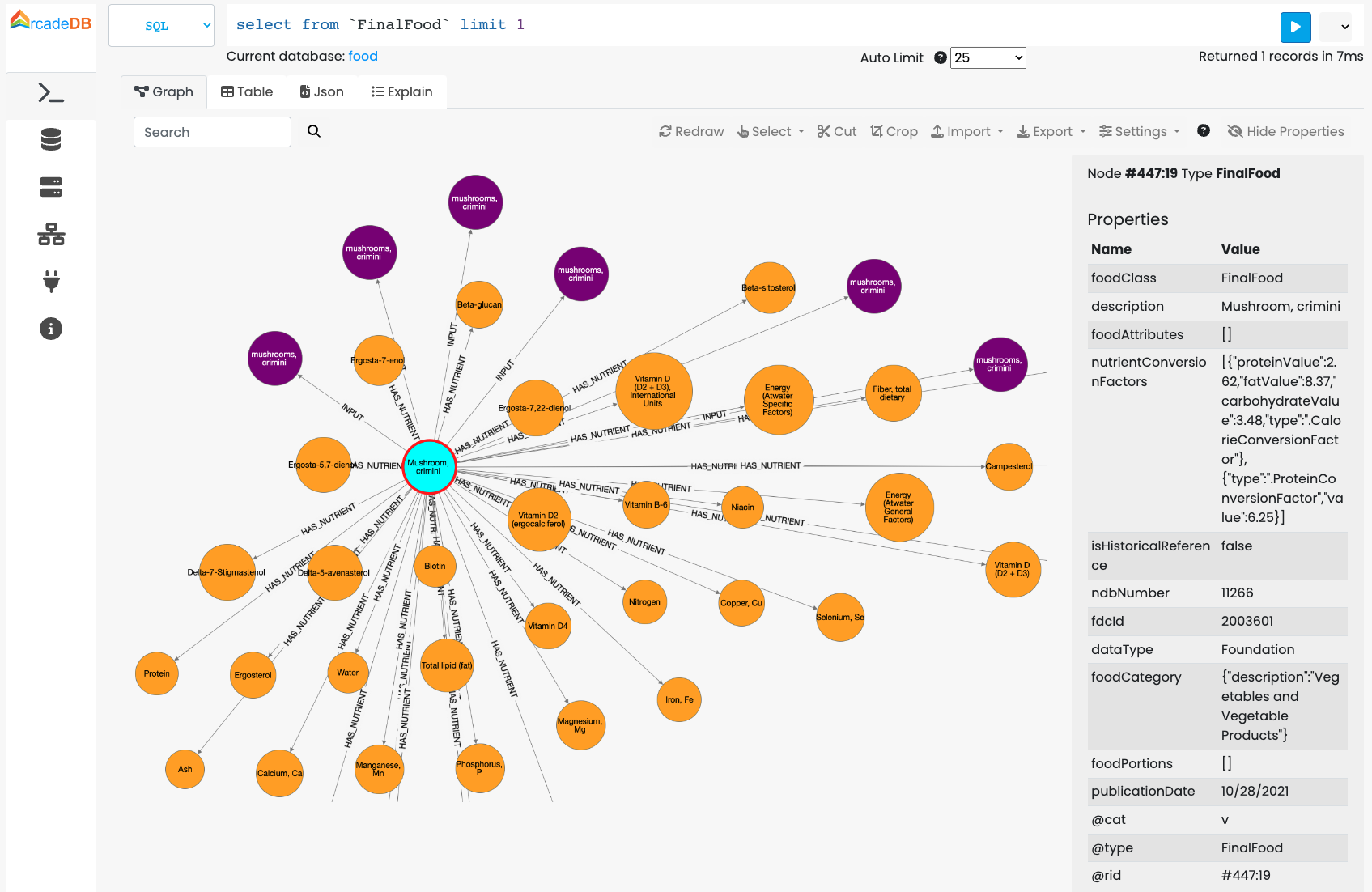
This command downloads the zip file from the USDA website and uses the mapping to create the graph from the JSON file.
The mapping file is a JSON snippet with directives about what to import, what to ignore and how to map edges with JSON objects. Below all the supported tags:
-
@cat: is the category of record to use between "v" for vertex, "e" for edge and "d" for document -
@type: is the type name to use on record creation. If the type doesn’t exist, it’s implicitly created during the import -
@id: is the property that works as primary key. if not already defined, a unique index is created on the configured@idproperty -
@idType: is the type of the primary key in the@idproperty. If not defined, the type is taken from the first value found. In case of numbers, the JSON parser always uses DOUBLE as a type. You can, for example, use LONG to force using LONG instead of DOUBLE -
@cardinality: if "no-duplicates", the edges are not created if there is an edge of the same type between the two vertices -
@strategy: represents the strategy to use when the record with the configured@idalready exists By default the existent record is used, but the "merge" strategy allows to merge the current record with the existent one. The current properties will overwrite the existent ones -
@in: used for edges and represents the destination vertex for the edge -
@ignore: ignore the property, do not import into the database